How to Use Machine Learning in Clinical Research

Clinical research is very complex, mainly because the questions we answer are almost always multivariate problems, and machine learning can aid clinical researchers in making sense of it.
Subjects in a clinical trial differ by myriad factors. Age, gender, and weight at baseline are just a few of many examples of features that make every subject who takes an investigational drug or placebo different from one another, complicating the study analysis. These features constitute various “subgroups,” which may have very different responses to study treatments.
Clinical researchers, therefore, spend lots of time grappling with one question: can we infer which subgroups may experience some adverse event?
In fact, there is a related question that is perhaps asked less often in clinical research, but that could be ground-breaking for patient care and health operations: can we predict which subgroups may be expected to respond particularly well or poorly to a treatment or experience an adverse event? This is where the benefits of machine learning come in.
It’s important to note the research question of inference, inferring the effect subject features or groups have on the likelihood of an event, is very different from prediction, the art of using algorithms and pattern detection to predict the onset of an event before it occurs. However, a set of tools that can aid clinical researchers in their inference of the subgroups of interest and take them to the next step of prospective prediction is machine learning.
Examples of inference
Statistical models are traditionally used for inference of important subgroups and features. Methods like regression or the Cox proportional hazards model can be used to model the effect a feature has on the logarithmic odds of an outcome or the hazard ratio concerning that feature, respectively.
Below is an example of logistic regression using anonymized data in a double-arm study. Subjects are randomly assigned to one of three groups: placebo or a high or low dose of an investigational treatment. Other features are used in the model: age, gender, height at baseline, weight at baseline, duration of disease, and total Mini-Mental Stage Evaluation score (MMSE).
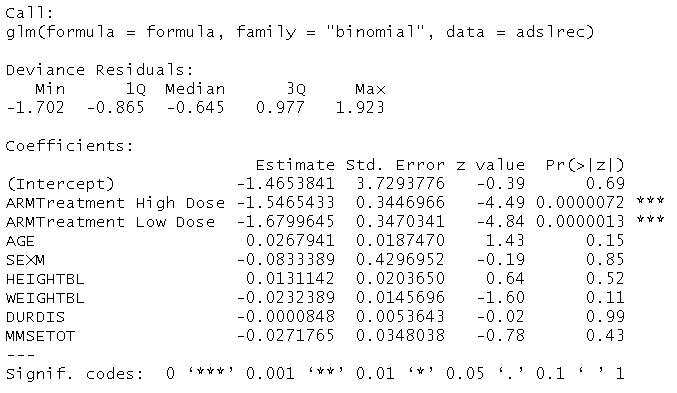
We find that at a 0.05 significance level, the only significant subject feature is the arm of the study. Receiving a high dose of the treatment is expected to result in a decrease of -1.5465 in the logarithmic odds of event occurrence compared to the placebo.
In fact, receiving a low dose of the treatment is expected to result in a decrease of -1.6800 in these logarithmic odds relative to the placebo. However, none of the effects of the other features are significant at the 0.05 level. At first glance, the fact the arm of the study is the only important feature is a compelling takeaway.
One must remember that all methods – including regression models – are subject to several assumptions. For instance, a simple logistic regression models the logarithmic odds of the outcome linearly in terms of the other features. The notion that these relationships are linear constitutes a very stringent assumption. It is worth employing other techniques to assess if they return the same or similar results. If so, audiences can walk away confident that results are robust to the underlying assumptions of models used.
One popular machine learning method in clinical research is the Random Forest. Part of the output for the Random Forest is the “variable importance plot.”
While the algorithm is complex, the plot’s interpretation is straightforward: based on the model, the higher the “mean decrease in Gini index” for a given feature, the more “important” that feature is. Using the same anonymized data, we compare the results of the random forest to the logistic regression results as follows:

The interpretation of the Random Forest variable importance plot could not be more different from that of the logistic regression. Not only is the arm of the study no longer the only important variable used – there are four variables that are more important!
Many other machine learning algorithms, such as gradient boosting or decision trees, include output that can be used to rank the importance of features. This illustrates how these algorithms can be used independently for inferential purposes, but can also play an important role in supplementing the knowledge gained from traditional statistical methods.
Learn about our Data Science support.
Prediction in clinical research
Inference is not the primary goal in most use-cases for machine learning in clinical research. Often, the objective is to build an accurate classifier. In reality, a clinical outcome is discrete: a subject either experiences an event or does not.
A strong classifier should have strong sensitivity (detection of events before they occur), strong specificity (detection of progression-free survival (PFS)), and strong positive predictive value (the precision of the model’s event predictions). The challenge in this problem is that there is an inverse relationship between sensitivity and specificity, as well as between sensitivity and positive predictive value.
Suppose we use 70 percent of our anonymized data to train a popular machine learning classifier called the Elastic Net, for instance. We use the remaining 30 percent of the data to evaluate its performance. We then arrive at the following output:

Of 30 subjects who experience an event, the model accurately prospectively detects 18 (60 percent) of them. Similarly, it accurately detects 36/45 (80 percent) of the subjects who experience PFS; 18/27 (66.7 percent) of the time when it predicts an event, it is correct.
The quality of this model is in the eye of the beholder; some clinical researchers may find it a useful tool already. However, it is a quick tool. With extra time, it can be tuned for increased predictive power or to weight one of the metrics such as sensitivity or specificity based on greater importance to clinical researchers.
Machine learning in clinical research can help to make decisions on the most important subject features and confounding variables in a study. Furthermore, using these algorithms for predictive purposes can help take clinical analysis and patient care from reactive to proactive. The possibilities for machine learning to aid in clinical research, patient care, and health operations are truly endless if one looks for them.
To learn more about machine learning, fill out the form below to register for our on-demand webinar.
Suggested For You

perspectives
June 6th, 2024
Datacise and Diversity in Patient Enrollment: Combining Geospatial and Demographic Data to Aid Site Selection

perspectives
April 29th, 2024
Validation of Clinical Dashboards for Decision Making

perspectives
December 14th, 2023
Data Provenance in Real World Evidence Studies, Explained!

perspectives
September 8th, 2023
FDA and the Real-World: Key Changes from Draft to Final Guidance on RWD and RWE

perspectives
November 30th, 2022
Exploring the use of Real-World Evidence in Regulatory Decision Making Under PDUFA VII

perspectives
August 16th, 2022
Natural Language Processing in Healthcare: The Pros, Cons, and Potential Impact

perspectives
May 31st, 2022
Attending the 2022 PHUSE US Connect: A Data Scientist’s Experience

perspectives
July 10th, 2020
Why COVID-19 testing devices require a high level of specificity

perspectives
February 7th, 2020
The New Roaring 20s: 12 Experts Provide Pharmaceutical Insights for the Decade Ahead

perspectives
August 22nd, 2019
Using Real World Data in Drug Development: Five Questions with Vijay Ivaturi, PhD

perspectives
July 18th, 2019
Using Real World Data in Pharmaceuticals: A Conversation with Chris Hurley

perspectives
January 10th, 2019
How Real World Data is Changing the Pharmaceutical Industry